Biological Specimen Digitisation — Life Sciences
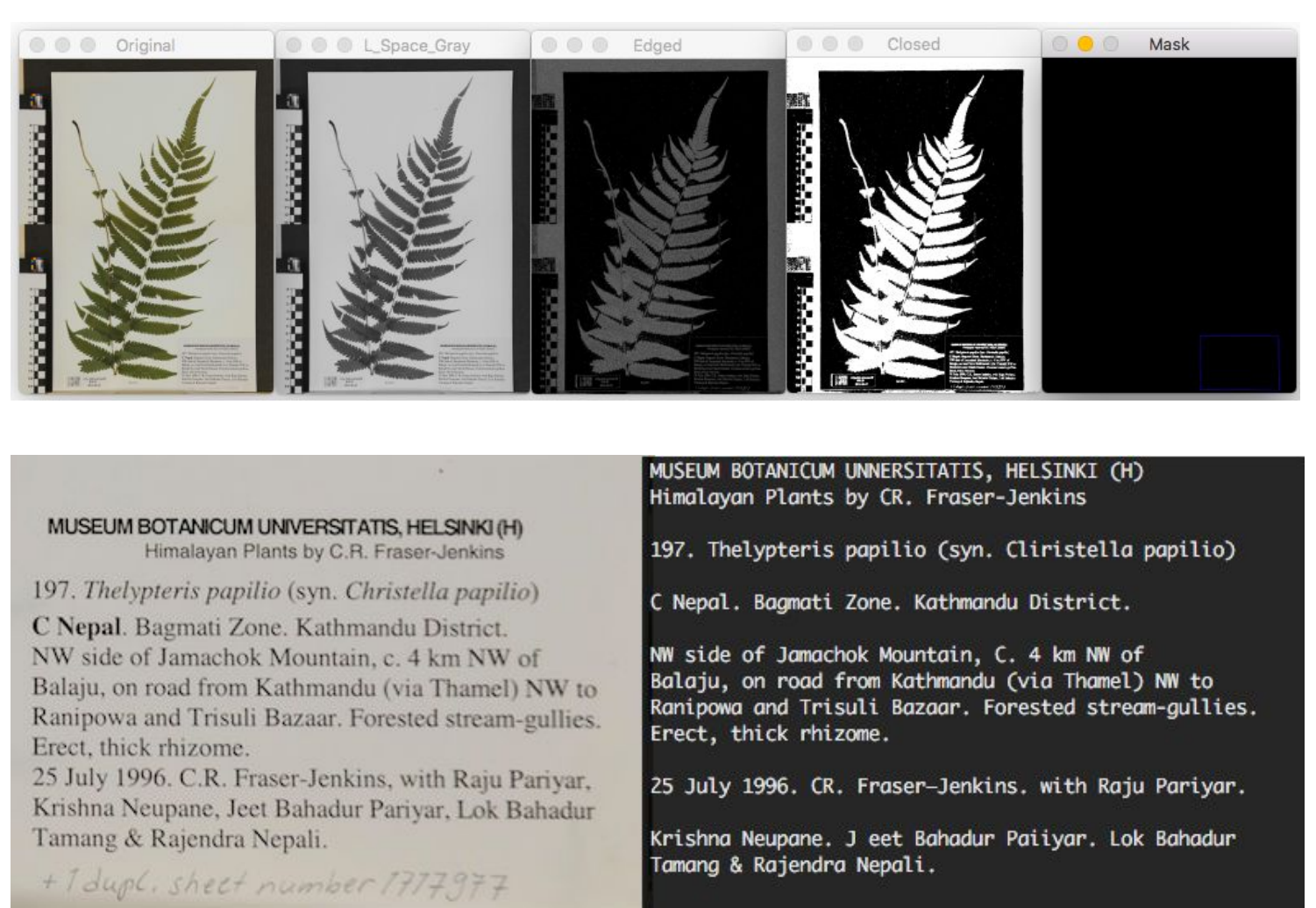
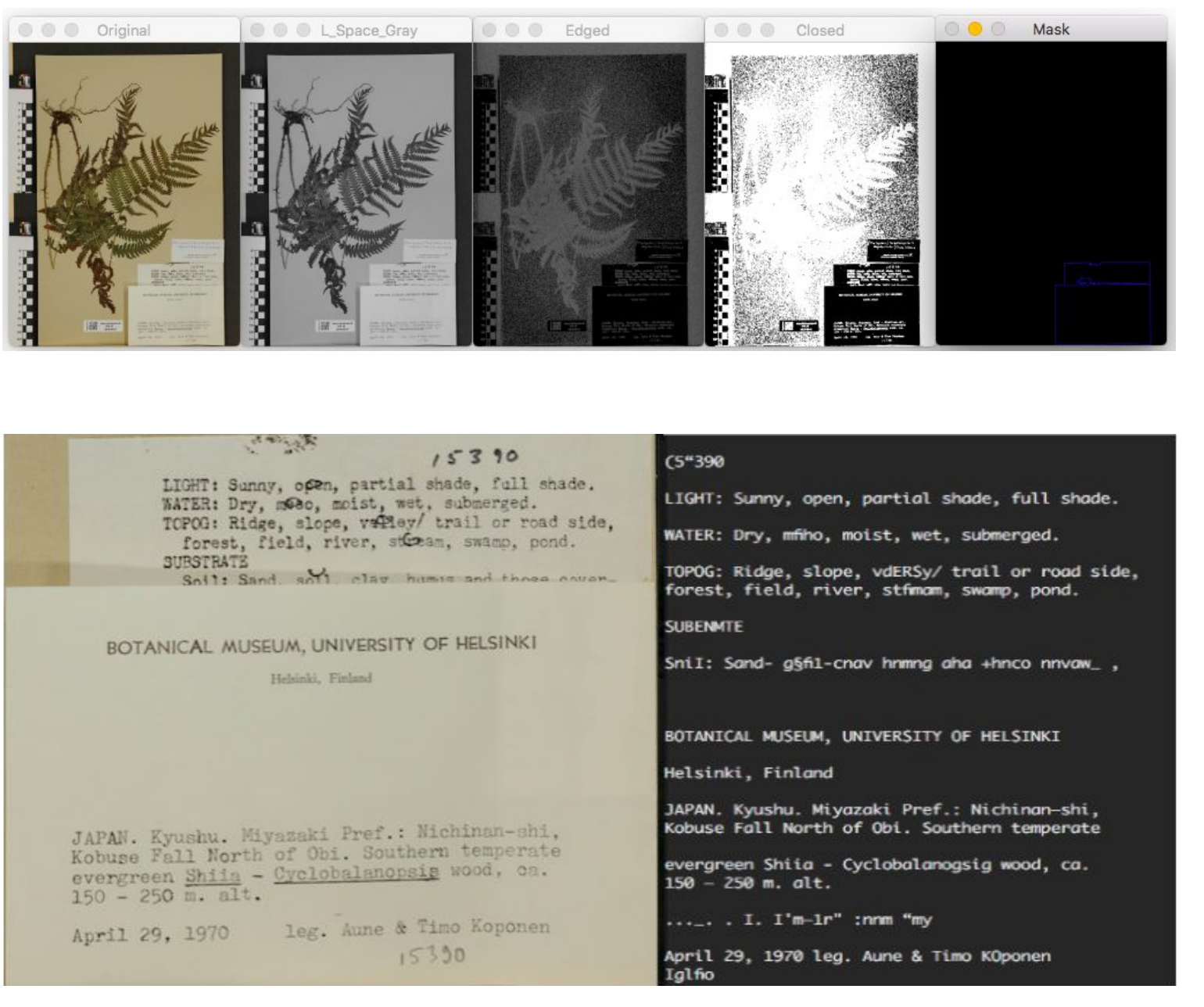
Built an end-to-end digitisation pipeline for biological specimens — herbaria and insect collections — for Digitarium, Finland's specialist natural history digitisation centre. The system automatically detects and segments label regions from high-resolution specimen images, extracts printed text via Tesseract OCR, and applies NLP to parse and structure key taxonomic metadata: species name, collector, geographical location, and collection date. Designed to accelerate large-scale biodiversity research by making historically inaccessible specimen data searchable and machine-readable.
Tools & Architecture Used: - Python - Opencv - NLP - Machine Learning - Matlab
 Thiyaga Bot
Thiyaga Bot